DuckDB: The Missing Analytical Layer
January 3, 2026
Over the last decade, PostgreSQL has become the default database for many teams. It is reliable, battle-tested, and exceptionally good at what it was designed for: transactional workloads.
But as data volumes grow and analytical use cases creep into application stacks, many teams quietly discover that SQL alone is not enough — how SQL is executed matters just as much.
This is where DuckDB enters the picture.
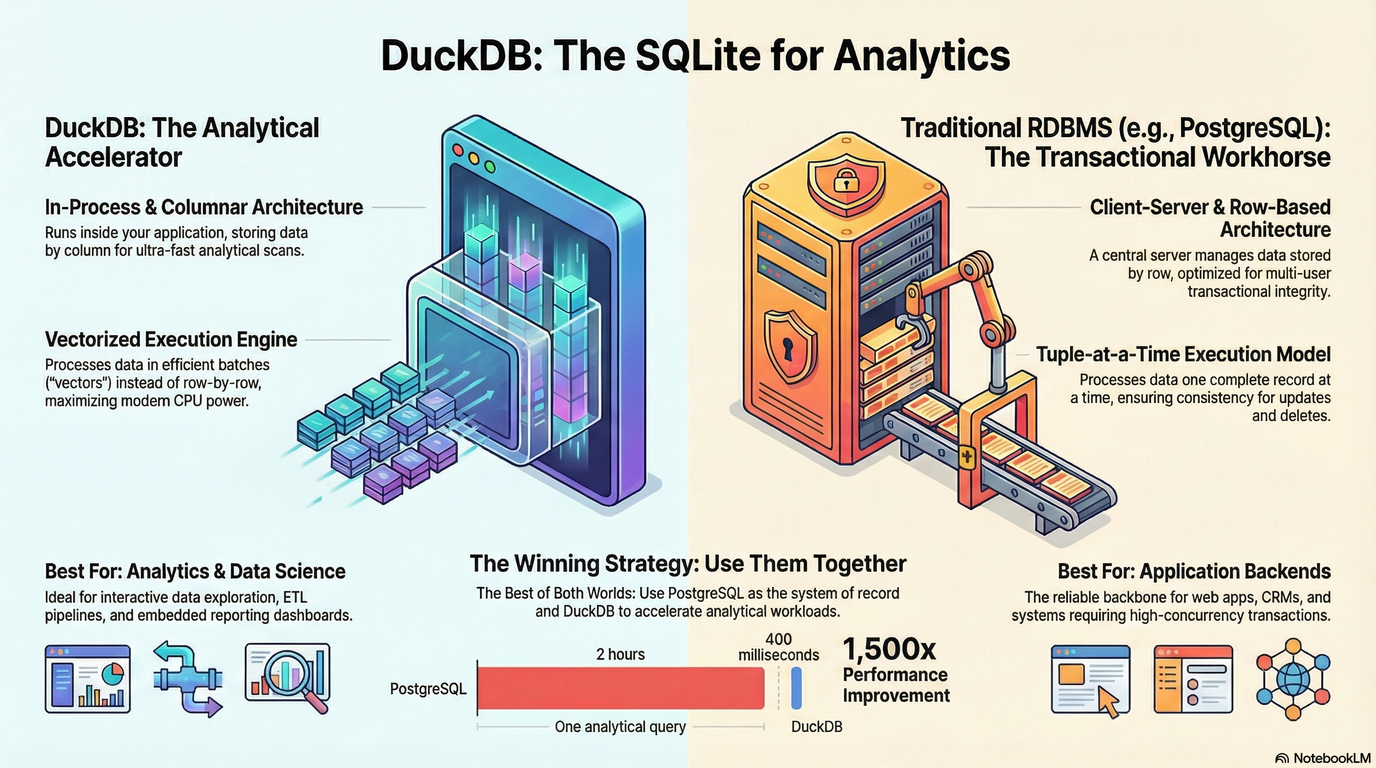
DuckDB is often described as "SQLite for analytics." That description is accurate, but undersells what makes DuckDB special: it is an in-process, columnar, vectorized analytical database optimized for scanning and aggregating large amounts of structured data at extremely high speed.
The result is a tool that feels familiar, yet behaves fundamentally differently from traditional row-based databases like PostgreSQL.
The Core Architectural Difference
To understand why DuckDB can be dramatically faster for analytics, we need to look at execution models.
PostgreSQL: Transactional First
PostgreSQL is a client–server, row-oriented system. Each row is stored and processed as a unit, and queries operate in a tuple-at-a-time fashion. This design excels at:
- High concurrency
- Frequent inserts, updates, and deletes
- Strong transactional guarantees (ACID)
But for analytical queries — such as full table scans, aggregations, or wide GROUP BY operations — this model becomes inefficient. PostgreSQL ends up touching far more data than necessary and pays overhead per row. Indexes help, but only when the query pattern matches the index structure. For exploratory analytics, they rarely do.
DuckDB: Analytics by Design
DuckDB takes the opposite approach:
- Columnar storage: Only the columns needed by a query are read.
- Vectorized execution: Data is processed in batches (vectors), not row by row.
- In-process execution: No network overhead, no context switching between client and server.
This design allows DuckDB to fully utilize modern CPU caches, SIMD instructions, and memory bandwidth. For read-heavy analytical workloads, this difference is not incremental — it is orders of magnitude.
What the Benchmarks Consistently Show
Across independent benchmarks and real-world case studies, a clear pattern emerges:
- Full table scans on hundreds of millions or billions of rows complete in seconds in DuckDB.
- The same queries in PostgreSQL often take minutes, even without concurrency.
- Complex aggregations (
GROUP BY, joins, filters) routinely show 10×–100× speedups. - In extreme cases (TPC-style analytical queries), speedups exceed 1000×.
These gains do not come from exotic hardware or proprietary extensions. They come from using an engine that is purpose-built for analytics. Importantly, DuckDB achieves this while retaining a full SQL interface. You do not have to abandon SQL, learn a new paradigm, or move data into a remote system just to analyze it efficiently.
When DuckDB is the Right Tool
DuckDB shines in scenarios where data is large (millions to billions of rows), mostly read-only or append-only, and analyzed interactively or in batches. Common examples include:
- Data Science & Exploratory Analysis: Running complex analytical queries directly from notebooks or scripts without standing up infrastructure.
- ETL and Feature Engineering: Fast transformations, joins, and aggregations on raw datasets before feeding them into downstream systems or ML pipelines.
- Embedded Analytics: Shipping analytics inside an application without running a separate database service.
- Local Analytics on Large Files: Querying Parquet, CSV, or Arrow data directly with SQL, often faster than loading it into a traditional database first.
In all of these cases, DuckDB acts as an analytical accelerator.
When DuckDB is NOT the Right Tool
DuckDB is not a replacement for PostgreSQL in transactional systems. You should not use DuckDB as your primary database if you need:
- High-concurrency writes
- Frequent updates and deletes
- Multi-user transaction isolation
- Long-running, always-on database services
DuckDB is optimized for throughput, not concurrency. Trying to use it as a general-purpose OLTP database misses its strengths.
The Winning Strategy: Use Them Together
The most effective pattern is not DuckDB vs PostgreSQL — it is DuckDB + PostgreSQL. A common and powerful architecture looks like this:
- PostgreSQL as the system of record: Handles transactions, business logic, and operational workloads.
- DuckDB as the analytical engine: Periodically reads data from PostgreSQL (or from exported files) and executes heavy analytical queries at high speed.
This separation allows each system to do what it does best, without compromise.
Why This Matters Now
Modern applications increasingly blur the line between operational systems and analytics. Teams want insights faster, closer to where the data lives, and without complex infrastructure.
DuckDB fits this moment perfectly:
- It is simple to adopt.
- It integrates naturally with existing SQL workflows.
- It delivers performance that used to require specialized systems.
If your analytical queries feel slow, expensive, or overly complex to run in PostgreSQL, DuckDB is often the missing piece — not a replacement, but an upgrade.
If you'd like to use DuckDB in a multi-process environment, check out my open source project: Multi Dock on GitHub
Final Thoughts
DuckDB does not try to be everything. That is precisely why it works so well.
If you need fast, local, SQL-based analytics on large structured datasets, DuckDB is one of the most compelling tools available today. Used alongside PostgreSQL, it enables a clean separation between transactions and analytics, without forcing you to abandon the tools you already know.
Sometimes, the biggest performance gains do not come from tuning harder — they come from choosing the right engine for the job.